pandas 두번 째 정리
진행하기 전에 공부했던 내용들을 잠시 복습하는 타임을 갖도록 하자.
DataFrame은 열과 행을 갖춘 데이터타입이다. pd.DataFrame() 매서드를 사용해서 생성할 수 있으며 편집과 접근이 쉽고 표현방식도 좋기 때문에 애용한다.
loc과 iloc은 각각 인덱스와 행 번호를 기준으로 데이터에 접근하는 매서드였다. 물론 다른 방법으로도 행과 열에 접근할 수 있지만 이 두가지 방법이 가장 보편적으로 잘 쓰이고 있다.
DataFrame 다루기 심화
우린 DataFrame을 csv형태 파일로 받아서 사용을 할 수도 있고 우리가 직접 만들어서 사용할 수 있다.
이렇게 작성한 데이터의 양은 적을수도 있지만, 방대한 양일 수도 있다.
저번 시간에는 간단하게 이런게 있고 조작할 수 있다~ 라고만 얘기 했으나, 그렇게 넘어가기에는 꽤나 중요한 내용이기 때문에 어떻게 다루는 지에 대해서 지금부터 공부를 해보자.

뭔가 좀 많아 보이기는 하지만, 사실 파이썬 기초에 올렸던 내용들을 응용한 내용들이기도 하다.
먼저 처음 나온
print(ages[ages > ages.mean()])
print(ages > ages.mean())
이 두 문장은 겉으로 보기에는 굉장히 닮아있으나 매우 다른 출력값을 내보내므로 구분하는게 좋을 것 같아서 넣어봤다.
기본적으로 부등식을 프로그래밍 상에서 사용하게 되면, bool값으로 출력하게 된다. (True or False)
따라서 1문장은 사실상 print(ages[True])인 age값을 DataFrame에서 추출해 출력하게 되는 것이고, 2문장은 모든 age에 대한 bool값을 출력하게 되는 것이다.
manual_bool_values는 위에서 말한 1문장을 내가 지정한 형태로 원하는 사람의 age값을 뽑아내기 위해 지정해준 것이다.
print(ages + ages)
print(ages * ages)
print(ages + pd.Series([1, 100]))
이 문장은 DataFrame 값에 사칙연산이 적용된다는 것을 보여주기 위해 작성을 했는데, 3번 문장은 조금 특이한 결과값을 낸다.

NaN이란 누락값을 의미한다. null, Not-a-Number의 약자이다.
이런 일이 왜 발생하는지 한번 뜯어보자면,
내가 만들어 준 Series는 [1, 100] 두 칸 짜리 데이터이다.
이는 둘의 합산을 outer join 방식으로 하여, 두 데이터 모두 실존해야 값을 출력하기 때문에 NaN이 출력이 되었다.
그리고 마지막 두줄
print(scientists[scientists['Age'] > scientists['Age'].mean()])
scientists_dropped = scientists.drop(['Age'], axis=1)
사실 1번 문장은 위에서 설명한 것과 이미 같은 내용이다. scientist의 모든 데이터 값을 출력하되, Age의 값이 mean보다 높은 값의 데이터만 출력하겠다라는 의미이다.
drop은 내가 원하는 행열을 삭제시킬 수 있다. axis는 축의 방향으로 index와 column의 방향을 정해 지울 수 있다.

해당 코드는 작성한 DataFrame이나 수정한 csv파일을 저장하는 코드이다.
윗 줄과 밑 줄의 차이점은, 밑에 줄은 index를 지정해주지 않았다. 나머지는 같다.
데이터 병합 (Concatenate, Merge)
데이터들을 합치는 방법에는 여러가지가 있는데, 그 중 merge와 concat의 방식을 한번 배워보도록 할 것이다.
1. Concat
먼저 concat은 가장 단순하게 데이터를 병합하는 방법으로, concat함수를 선언해주면 된다.

연결해주고 싶은 방향에 따라 axis를 설정해주면 된다.
하지만 이렇게 단순하게 연결을 하게 되면 하나의 문제점이 생기는데,

어떤 문제점인지 알겠는가?
바로 index와 index번호가 수정되지 않고 그대로 연결하게 된다는 것이다.
이렇게 되면 iloc은 문제없이 작동될 수 있지만, loc의 경우에 문제가 생기는 것이다. 인덱스의 네이밍이 같기 때문에 작동은 될 지 언정, 내가 원하는 데이터 값을 뽑아내기는 힘들 수 있다.
따라서 우리는 다음 방법을 통해서 데이터 병합을 할 때 혼동을 줄이자.

이렇게 인덱스명을 수정해주면,

loc을 사용할 수 있는 형태로 출력이 가능하다.
만약 내가 병합을 하는데 각각 column의 name이 다 다르면 어떻게 병합이 될까?
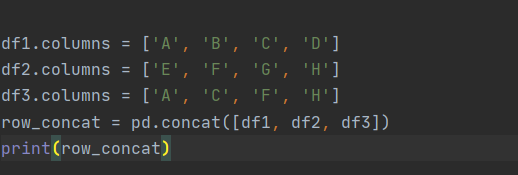

각 위치에 데이터가 존재하면 데이터 값을 합쳐 병합을 했고, 그렇지 않은 부분은 NaN값으로 대체되어 출력이 되었다.
이걸로 concat 역시 outer join 방식임을 알 수 있다.
2. Merge
merge의 특징은 공통적인 데이터를 기준으로 합병이 진행된다는 것이다.

가령 이러한 데이터가 있다고 치자.
이 데이터를 병합을 하게되면 어떤 결과가 추출이 될까?
결과는

이렇게 나온다.
우리가 지정해준 df1과 df2의 데이터에서 'name' column의 내용은 서로 다른데 어떻게 NaN의 값이 없이 데이터가 출력될 수 있었을까?
또, df1과 df2의 raws는 5줄인데 data_merged의 raws는 7줄이 모두 값이 존재하게 출력 된걸까?
이건 inner join 방식의 결과이기 때문이다.
outer join의 결과는 모든 출력값을 데이터의 존재 유무와는 상관없이 출력하게 되지만, inner join은 같은 name끼리의 값을 합쳐서 출력을 하게 된다.

쉽게 풀어서 설명하자면 이런 그림으로 설명이 가능하다.
하나의 input 값에 각각 대응하는 ways의 수만큼 출력이 되는 것이다.
merge는 기본적으로 이러한 방법을 채택하고 있지만, 우리가 지정을 해줌으로써 다른 방법으로도 병합이 가능하다.
방법은 outer, left, right 방식이 있다.
outer은 우리가 알고 있는 그 방법이 맞고, left는 병합할 때 기준으로 왼쪽에 있는 데이터를 모두 출력해주고, right는 오른쪽에 있는 데이터를 모두 나타내준다.

또 left, right는 내가 출력하고 싶은 column을 따로 설정해줄 수 있는데 이건 예제를 통해서 알아보도록 하자.
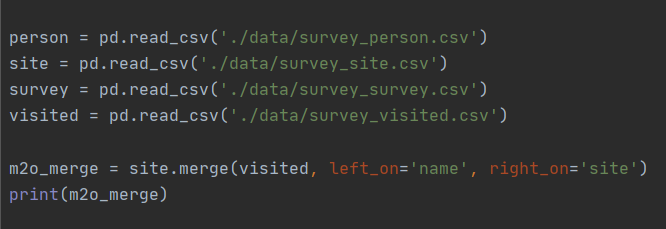
예제에서 실행한 것은 site 와 visited의 merge이다.
내가 알고싶은 것은 site에 방문한 visited의 날짜라고 했을 때, 방문한 장소의 name을 기준으로 병합을 진행하기 위해서 left와 right의 기준을 name과 site로 정했다. visited의 site는 site의 name에 해당하는 값이므로 병합을 진행해보면,

다음과 같은 결과가 나오게된다.
2. 누락값(NaN, nan) 처리
우리는 위의 예제들을 통해서 누락값을 발생을 경험해 보았고 이러한 데이터가 어떻게 발생하는지 알게되었다.
지금부터는 이 누락값들을 채우고 처리하는 방법을 알아보도록 하자.
결측값 분석하기
isnull 메서드를 사용하면, 데이터에 존재하는 누락값의 수를 알아낼 수 있다.

해당 데이터는
사진에서 보이듯이 그냥 보기에도 데이터가 듬성듬성한게 nan 값이 참 많게 생겼다.
지금부터 nan 값을 세아려 볼 것이다.


오래간만에 보는 귀여운 값들이 톡 튀어나왔다.
결측값은 총 1214개이고, guinea column의 결측값은 29개이다.
Dropna method
isnull 이외에 dropna를 이용해서 결측값을 세아리는 방법도 있다.
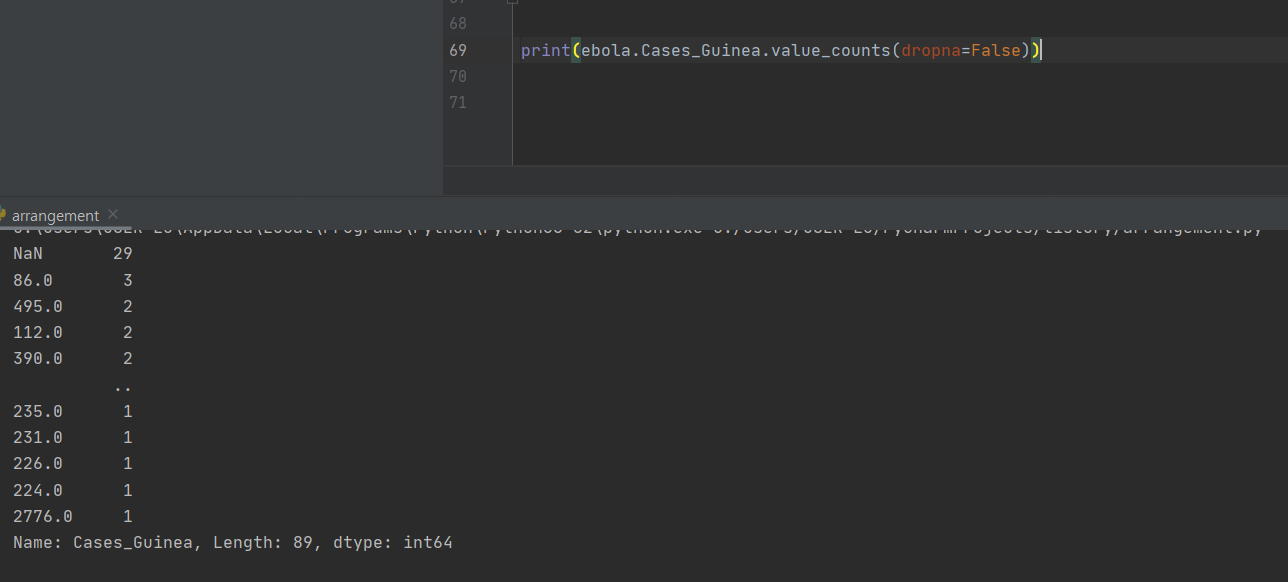
value_count로 고유값의 개수를 세아려주고, dropna를 통해서 결측값의 개수도 세아려 준다.
원래 dropna의 본래 사용법은 결측값을 제거하는데 사용하는 것이다.
dropna매서드에 axis 값을 정해주면 원하는 방향으로 누락값 제거가 가능하다.
결측값 채우기
누락값 채우기를 할 때 사용하는 매서드는 fillna이다.
fillna를 사용해서 누락값을 채울 시에는 모든 값이 파라미터 값으로 바뀐다.
ex) df.fillna('A')이면 nan 값이 모두 A로 대체되게 된다.
혹은 ffill, bfill이라는 값을 사용해주게 되면, 각각 위의 값 복사, 아래의 값 복사를 해서 데이터를 채워넣는다.

2번째 출력값에서는 상위의 값이 존재하지 않기 때문에 NaN으로 출력이 된 것이다.
그리고 interpolate는 위아래의 평균값을 누락값에 채워넣어준다. 같은 이유로 NaN값이 출력된 것이다.
이상으로 pandas에 대한 정리를 마친다 ㅠㅠ
정말 배울 것이 많고 힘들지만 필수적이라는게 공부를 할 수록 느껴지는 것 같다......
20-6-27
'데이터 분석 > 파이썬' 카테고리의 다른 글
| 데이터 시각화 그래프 (0) | 2021.06.29 |
|---|---|
| numpy 라이브러리 (0) | 2021.03.23 |
| 판다스를 이용한 데이터 정제 (0) | 2020.06.17 |
| 셀레니움을 이용한 웹크롤링(Web crawling) (0) | 2020.06.03 |
| 엑셀 심화 (0) | 2020.06.02 |