
오늘은 파이썬 csv 사용하는 것에 대한 기본을 정리해보겠다.
우선 csv(comma-separated values)란?
: 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일이다.
확장자는 . csv이며 MIME 형식은 text/csv이다.호환되지 않는 포맷을 사용하는 프로그램 끼리 자료를 전달할 때 사용하는데 쓰인다.
파이썬에선 이것으로 text 파일 뿐 아니라 xlsx 파일 같은 것도 건들이곤 한다.
csv 파일 읽어오기

우선 csv 파일을 다루기 위해서는 import 라는 명령어를 통해 csv파일을 다룰 수 있는 모듈을 가지고 와야한다.
그 이후 open 이라는 명령어를 통해서 읽어올 파일을 정한다.
그 뒤 'r' 은 모드를 정하는 것인데 기본적으로 'r' : read mode, 'w' : write mode 를 사용한다.
기본적으로 read 모드로 가져올 경우에는 경로를 지정하거나 파이썬 폴더 안에 csv파일이 존재해야 읽어올 수 있다.
그 후 읽어온 파일을 출력해보기 위해, reader라는 객체를 사용하여야 한다. csv파일에 담겨있는 내용을 리스트 형식으로 한 줄씩 가져오겠다는 선언을 해주는 것이다.
그 후 반복문을 통해 한 줄씩 출력해서 가져온다.
csv 파일 쓰기

불러오는 방식은 read 모드와 똑같다. 다만 write모드는 파일을 새롭게 작성할 수 있으므로 반드시 그 파일이 존재할 필요는 없다.
그리고 뒤에 있는 newline은 파일 쓰기 형식과 관련된 얘기인데, write모드로 작성할 시 기본적으로 엔터가 들어가게 되어있다.
그러므로 writer 라는 객체를 사용할 때 한 줄씩 가져오는 것 + 엔터를 하게되면 두 줄씩 띄워서 글을 작성해버리게 되는 것이므로 띄우지 않겠다 라는 의미로 작은 따옴표 사이에 아무것도 넣지 않고 사용하는 것이다.
writerow 메서드는 새롭게 list 데이터를 한 줄 넣겠다는 의미이다. 따라서 이 메서드 뒤에 list로 작성을 하는 것이 기본이다.
∴f.close는 열었던 파일을 닫아준다는 의미로 보통 프로그램이 종료되면 같이 종료되어 굳이 써주지 않아도 괜찮지만, write모드로 글을 작성할 때 파일이 열려있으면 오류가 발생하므로 닫아주는걸 습관화하는 것이 좋다.
엑셀 파일 다뤄보기

위에서 설명한 csv파일 읽기와 똑같은 형식으로 진행할 수 있다.
csv파일을 microsoft Excel로 연결을 해준 후 위와 같은 코드를 실행하게 되면,

짠~ 위와 같은 데이터가 쭉 나열되었다! 내가 실행한 data.csv 파일 안에는 첫번째 리스트에 있는 항목들로 총 1000개의 데이터가 존재하며, 1001개의 리스트로 구성되어 읽어올 수 있었다.
그러나 나는 읽기만 할려고 파이썬을 배우는 것이 아니라 읽고 쓰고 수정하기 위해 사용하므로 이에 대해서 알아보자.
다음 과정을 실행하기 위해서는 openpyxl이라는 라이브러리가 필요하므로 pip를 이용해 설치해주도록 하자.
∴엑셀 파일 쓰기를 설명하기 전에 openpyxl을 설치했다면, csv파일로 읽어오는 것 말고도 load_workbook('파일명.xlsx')를 사용해 읽어올 수 도 있다.
엑셀 파일 쓰기

wb = Workbook() 은 엑셀 파일의 시트를 하나 새로 만들겠다는 소리이다.
그 이후 active를 통해서 wb의 시트를 활성화 시켜 동작을 수행하겠다라는 행동을 취했다. 이건 open과 비슷한 의미로 받아들이면 될 것 같다.
활성화 된 시트의 A1열에 HELLO! 라는 글자를 새겨넣은 뒤, test라는 이름으로 파일을 저장해 보았다.
결과는..

잘 저장되어 무사히 실행하였다!
이것말고도 openpyxl 에 내장되어 있는 객체는 많다.
wb.create_sheet를 통해 내가 원하는 새로운 시트를 만드는 것도 가능하고,
test['A1'].value를 통해 내가 원하는 열의 값을 가져오는 것도 가능하다.
이것까지 배웠으면 많이 배운 것 같지만, 왜 csv와 xlsx을 같이 가져왔겠는가..! 이것으로 무엇을 할 건지는 밑에서 차근차근 배워보자.
csv를 통해서 엑셀파일을 수정해보자.

한 줄씩 분석해보자!
먼저 csv파일 읽어오기 부분은 설명했으니 생략하고,
list = []는 비어있는 새로운 리스트를 하나 생성하겠다는 것이다.
그 후 reader 객체를 통해 오픈한 파일을 한 줄씩 읽어오면서 반복문을 통해 list에 한 줄씩 추가한다는 것이다. i[1]은 data.csv의 한 줄 중에서 두번째 리스트, [1, 2, 3]이 있으면 2를 가져오겠다는 소리이다.
다음은 data_n라는 새로운 파일을 개설하며 이것을 쓰기모드로 하여 가져온 리스트의 내용 덮어씌워 저장하려한다.
마찬가지로 writer 객체를 통해 비어있는 한 줄씩 가져오면서 반복문을 통해 리스트에 있는 내용을 써주겠다!
무사히 실행과정을 마치면,,

무사히 내가 원하는 내용을 가져왔음을 알 수 있다!
여기서 조금만 더 응용하면, 한 셀 내에서도 내가 원하는 내용만을 가져올 수 있다.

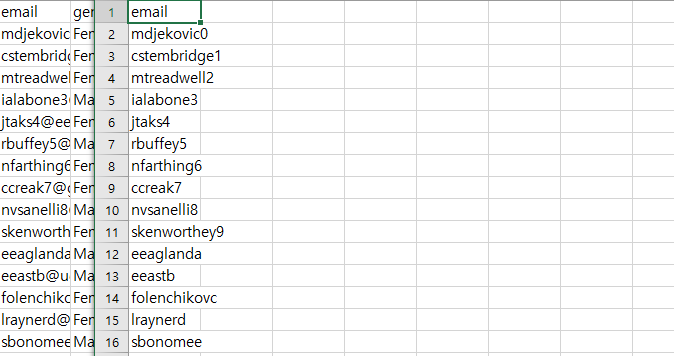
별 다를 것 없이 작성한 것 같지만, 어제 설명했던 split이라는 객체를 통해 이메일에서 @뒷부분인 도메인을 때고 내가 원하는 데이터를 저장하고자 위와 같은 코드를 작성한 것이다.
그 후 0번째를 불러온 것은 내가 찾고자하는 부분이 아이디 부분이므로 작성해준것이다. 만약 도메인을 조사하고 싶다면 1을 해주거나 -1을 해주면 된다.
(내가 해본 결과 도메인이 존재하지 않는 즉, 아이디만 있는 데이터가 있어 null값이 존재해 1은 출력되지 않았다. 내가 가지고 있는 데이터 상으로는 -1을 해주면 정상적으로 출력이 된다.)
결과:
2020.05.30
'데이터 분석 > 파이썬' 카테고리의 다른 글
| pandas 데이터 정제 (2) (0) | 2020.06.27 |
|---|---|
| 판다스를 이용한 데이터 정제 (0) | 2020.06.17 |
| 셀레니움을 이용한 웹크롤링(Web crawling) (0) | 2020.06.03 |
| 엑셀 심화 (0) | 2020.06.02 |
| 파이썬 기초 (0) | 2020.05.30 |