처음 열었을 때 아 그냥 문자열 파싱 문제인가 생각했지만 생각보다 까다로운 구현과정이 내포된 문제였다.
정말 다행스럽게도 연산자가 3개 밖에 없고, 문자열의 길이도 100이 제한이었기 때문에 시간 복잡도를 고려하지 않고 문제를 풀어나갔다.
<정답 코드>
from itertools import permutations
from collections import deque
def ex_split(ex):
reg = []
tmp = ''
for i in ex:
if i.isdigit():
tmp += i
else:
reg.append(int(tmp))
reg.append(i)
tmp = ''
if tmp:
reg.append(int(tmp))
return reg
def solution(expression):
answer = 0
expression = ex_split(expression)
for case in permutations(['+', '-', '*'], 3):
temp = deque(expression)
for operator in case:
ans = deque()
while len(temp):
cur = temp.popleft()
if cur == operator:
a = ans.pop()
b = temp.popleft()
ans.append(eval(str(a)+cur+str(b)))
else:
ans.append(cur)
temp = ans
answer = max(abs(temp[0]), answer)
return answer
🔎[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.] 카카오 초등학교의 "니니즈 친구들"이 "라이언" 선생님과 함께 가을 소풍을 가는 중에 징검다리가 있는 개울을 만나서 건너편으로 건너려고 합니다. "라이언" 선생님은 "니니즈 친구들"이 무사히 징검다리를 건널 수 있도록 다음과 같이 규칙을 만들었습니다.
징검다리는 일렬로 놓여 있고 각 징검다리의 디딤돌에는 모두 숫자가 적혀 있으며 디딤돌의 숫자는 한 번 밟을 때마다 1씩 줄어듭니다.디딤돌의 숫자가 0이 되면 더 이상 밟을 수 없으며 이때는 그 다음 디딤돌로 한번에 여러 칸을 건너 뛸 수 있습니다.단, 다음으로 밟을 수 있는 디딤돌이 여러 개인 경우 무조건 가장 가까운 디딤돌로만 건너뛸 수 있습니다.
"니니즈 친구들"은 개울의 왼쪽에 있으며, 개울의 오른쪽 건너편에 도착해야 징검다리를 건넌 것으로 인정합니다."니니즈 친구들"은 한 번에 한 명씩 징검다리를 건너야 하며, 한 친구가 징검다리를 모두 건넌 후에 그 다음 친구가 건너기 시작합니다.
디딤돌에 적힌 숫자가 순서대로 담긴 배열 stones와 한 번에 건너뛸 수 있는 디딤돌의 최대 칸수 k가 매개변수로 주어질 때, 최대 몇 명까지 징검다리를 건널 수 있는지 return 하도록 solution 함수를 완성해주세요.
출처: 프로그래머스
[입출력 예]
출처: 프로그래머스
사람의 직관으로는 어렵지 않은 문제나, 컴퓨터를 통해 구현하고자 하니 까다로운 문제였다.
stones 배열 제한이 200,000, 각 원소 제한이 200,000,000이고 효율성 테스트까지 통과해야하므로 단순히 모든 돌을 1씩 감소시키면서 문제를 풀면 시간 제한을 통과할 수 없다.
그래서 처음 생각한 방법은, stone배열을 정렬해서 k번째 원소만큼 빼고 시작하는 것이었다.
이 방법은 결국은 1씩 감소 시키는 걸 조금 더 가속화 시켜줄 뿐, 시간 복잡도 개선에 별 기여를 하지 못했다.
방법은 '이분 탐색'에 있었다.
처음에 이분 탐색이라는 힌트를 봤을 때 돌의 순서가 정해져있어서 정렬하지 못하는데 이분 탐색이 가능한가? 의문을 가졌었다. (이분 탐색은 원래 정렬된 배열에 시행하는 탐색 알고리즘이다.)
<정답 코드>
def solution(stones, k):
left, right = 0, max(stones)
while left <= right:
mid = (left+right)//2
flag = 0
for s in stones:
if s-mid < 0:
flag += 1
if k <= flag:
break
else:
flag = 0
if k <= flag:
right = mid-1
else:
left = mid+1
return left-1
이 문제에서 이분 탐색의 개념은 배열에 적용하는게 아니라 윈도우(범위)에 적용되는 것이었다.
접근은 아래와 같다.
stones원소의 최대 값을 구한다.
돌에서 뺄 원소 값을 left와 right의 중간값으로 하여 전체 돌을 순회한다.
flag를 통해서 0보다 작은 값이 되는 돌들을 카운트 한다.
0보다 크면 flag를 0으로 초기화한다.
flag가 k가 되면 for문을 탈출한다.
이후 윈도우의 크기를 절반으로 줄여 다시 진행한다.
이 방법을 시도하면서 들었던 의구점은 left나 right의 값이 stone의 원소와 일치하지 않는다면 정렬을 통해 진행했던 내 방법보다 나은게 뭐가 있지? 라는 생각이었다.
그래서 다시 값의 개수 자체를 줄이고자 set을 활용해서 진행해보고자 했으나, set으로 전환하고 list로 바꾸고 sort까지 하는 과정에서 시간 복잡도를 너무 잡아먹어서 포기하기로 했다..
*해당 문제를 deque와 sliding window maximum을 통해 해결할 수 있다는 글을 보았다. 원리 자체가 아예 이해 안가지는 않았지만, 여러번 작성해봐도 실제로 작동하는 코드를 짤 수 없었다. 이후에 다시 한번 도전해보고자 한다.
🔎개발팀 내에서 이벤트 개발을 담당하고 있는 "무지"는 최근 진행된 카카오이모티콘 이벤트에 비정상적인 방법으로 당첨을 시도한 응모자들을 발견하였습니다. 이런 응모자들을 따로 모아 "불량 사용자"라는 이름으로 목록을 만들어서 당첨 처리 시 제외하도록 이벤트 당첨자 담당자인 "프로도" 에게 전달하려고 합니다. 이 때 개인정보 보호을 위해 사용자 아이디 중 일부 문자를 '*' 문자로 가려서 전달했습니다. 가리고자 하는 문자 하나에 '*' 문자 하나를 사용하였고 아이디 당 최소 하나 이상의 '*' 문자를 사용하였습니다. "무지"와 "프로도"는 불량 사용자 목록에 매핑된 응모자 아이디를 "제재 아이디" 라고 부르기로 하였습니다.
출처: 프로그래머스
문자열 처리 문제는 언제나 귀찮음을 동반한다.
그리고 해당 문제는 브루트포스가 아닌 방법으로 접근하면 상당히 어렵게 느껴졌다.
제한사항을 잘 읽어보고 바로 브루트포스를 떠올렸다면 상당한 침착한 실력자임이 분명하다..
<정답 코드>
from itertools import permutations
import re
def solution(user_id, banned_id):
n = len(banned_id)
answer = set()
banned_id = [i.replace('*', '.') for i in banned_id]
for per in permutations(user_id, n):
tmp = list(per)
for i in range(n):
if not(re.match(banned_id[i], tmp[i]) and len(tmp[i]) == len(banned_id[i])):
break
else:
tmp.sort()
answer.add(tuple(tmp))
return len(answer)
개인적으로 permutations, combinations를 사용하지 않는 것을 선호하지 않는다.
옛날에 처음 itertools를 알게 됐을 때 신나게 사용하다가 항상 시간초과를 먹었기 때문에 친하지 않다..
하지만 이 문제에서는 배열의 길이가 최대 8이므로 permutation을 이용해도 시간을 많이 잡아먹지 않아 결국은 사용하게 됐다.
접근은 아래와 같다.
user_id에서 banned_id 길이 만큼의 아이디를 순열로 추출한다.
순열로 추출하는 이유: user_id 배열의 순서와 상관없이 banned_id가 구성되었기 때문
추출된 순열 전체를 탐색하면서 banned_id 전체와 매칭되는지 확인한다.
매칭되는가는 re 모듈을 활용해서 진행한다.
re.match 함수는 '.'이 입력된 자리에는 어떤 문자든 대체 가능하기 때문에, 우선적으로 banned_id의 원소를 구성하는 '*'을 '.'로 대체하는 작업을 진행하고 순회한 것이다.
또한, match는 길이와 상관없이 "해당 문자들로 시작한다면 True"이기 때문에 길이 검사를 따로 해줘야한다.
처음에는 match도 직접 구현하려하고, permutation이 아닌 match되는 문자들을 추출한 다음 조합하려했으나, 결국은 banned_id의 길이만큼 반복해야한다는 것이 permutation과 같은 복잡도를 가져 그냥 가져다 쓰게 되었다.
파이썬이라는 언어가 가진 훌륭한 특징인 라이브러리들은 문제 해결에 큰 도움을 줄 수 있지만, 어떻게 동작하는지 정확히 파악하지 않고 쓰면 오히려 문제 해결에 방해가 될 수 있는 것 같다.
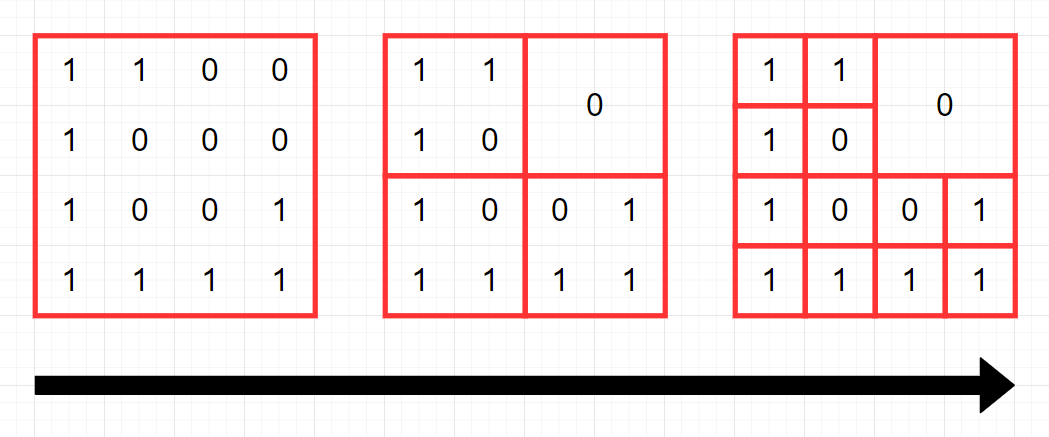
🔎0과 1로 이루어진 2n x 2n 크기의 2차원 정수 배열 arr이 있습니다. 당신은 이 arr을 쿼드 트리와 같은 방식으로 압축하고자 합니다.
구체적인 방식은 다음과 같습니다.
당신이 압축하고자 하는 특정 영역을 S라고 정의합니다. 만약 S 내부에 있는 모든 수가 같은 값이라면, S를 해당 수 하나로 압축시킵니다. 그렇지 않다면, S를 정확히 4개의 균일한 정사각형 영역(입출력 예를 참고해주시기 바랍니다.)으로 쪼갠 뒤, 각 정사각형 영역에 대해 같은 방식의 압축을 시도합니다.
arr이 매개변수로 주어집니다. 위와 같은 방식으로 arr을 압축했을 때, 배열에 최종적으로 남는 0의 개수와 1의 개수를 배열에 담아서 return 하도록 solution 함수를 완성해주세요.
출처: 프로그래머스
정사각형의 크기를 가진 2차원 배열을 4분할 하면서 풀어나가는 문제다.
처음에는 배열을 분할하는데 초점을 두고 문제를 풀어보려했다.
배열의 크기는 반드시 2의 배수인 정사각형 형태였기 때문에 항상 (배열의 길이)//2 만큼씩 행, 열을 분할해서 진행해나가면 4분할 하는 것은 그렇게 어렵지 않았다.
하지만, 분할된 사각형 안에서 0과 1의 개수를 세아리는 부분이 어렵다.
처음에는 재귀호출을 통해 분할이 불가능할 때 까지 분할한 후 list로 반환하는 답안을 작성하였다.
def quard_split(arr):
n = len(arr)
box = [[], [], [], []]
for i in range(n//2):
box[0].append(arr[i][:n//2])
box[1].append(arr[i][n//2:])
box[2].append(arr[n//2+i][:n//2])
box[3].append(arr[n//2+i][n//2:])
for i in range(4):
if 0 < sum(list(map(lambda x: sum(x), box[i]))) < (n//2)**2:
box[i] = quard_split(box[i])
return box
def solution(arr):
answer = [0, 0]
box = quard_split(arr)
print(box)
return answer
분할을 한 결과 배열을 출력해보면 위와 같이 중첩 배열 형식으로 나타나기 때문에 이것을 다시 flatten 하는 작업이 어려웠고, flatten했을 때 하나로 세아려지는 0, 1의 개수를 파악하기가 어려웠다. 그렇다고 무작정 for문을 돌리자니 깊이가 얼마인지 알 턱이 없었기 때문에 시간 복잡도 부분에서도 심각한 문제가 있었다.
정답에서는 실제로 분할하는 것이 아닌, count하는 것이 주 목적이었다.
<정답 코드>
def solution(arr):
answer = [0, 0]
_len = len(arr)
def quard_split(x, y, _len):
cur = arr[x][y]
for i in range(x, x+_len):
for j in range(y, y+_len):
if arr[i][j] != cur:
_len //= 2
quard_split(x, y, _len)
quard_split(x+_len, y, _len)
quard_split(x, y+_len, _len)
quard_split(x+_len, y+_len, _len)
return
answer[cur] += 1
quard_split(0, 0, _len)
return answer
이 방법은 분할을 모두 마친 후 분석을 진행하는 것이 아닌, 분할을 하는 과정에서 count를 한다. 다른 개념 자체는 이전에 작성했던 코드와 일치한다.
접근은 아래와 같다.
분할(혹은 전체) 사각형의 좌측 상단 꼭짓점을 좌표에서 시작해서 해당 사각형 내에서 시작점과 다른 값을 하나라도 가지면 다시 4분할을 진행한다.
반복문을 전부 순회하고 탈출하게 되면 시작점 값을 +1 해준다.
🔎해당 알고리즘은 분할 정복 알고리즘이라고 한다. 쉽게 풀리는 부분은 그냥 계산으로 진행하고, 아니면 작은 여러 개의 부분 문제로 구분해서 푸는 개념이다. 위 문제에서는 하나의 사각형을 점검하는 quard_split 함수가 분할해야 하는 상황에 처하게 되면 4개의 quard_split함수로 나뉘어 문제를 푸는 형태인 것이다.
코딩 테스트를 공부하다 보면 가장 자주 등장하는 탐색, DP, 트리, 그래프 등의 문제 이외에도 분할 정복, 이분 탐색, 슬라이딩 윈도우 등과 같이 한번씩 등장하는 어려운 문제들을 발견할 수 있다.
이런 문제일수록 더욱 꼼꼼히 기록하고 기억해서 코딩 테스트에서 우위를 가져갈 수 있도록 노력해야겠다.
🔎[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.] N x M 크기의 행렬 모양의 게임 맵이 있습니다. 이 맵에는 내구도를 가진 건물이 각 칸마다 하나씩 있습니다. 적은 이 건물들을 공격하여 파괴하려고 합니다. 건물은 적의 공격을 받으면 내구도가 감소하고 내구도가 0이하가 되면 파괴됩니다. 반대로, 아군은 회복 스킬을 사용하여 건물들의 내구도를 높이려고 합니다. 적의 공격과 아군의 회복 스킬은 항상 직사각형 모양입니다.
예를 들어, 아래 사진은 크기가 4 x 5인 맵에 내구도가 5인 건물들이 있는 상태입니다.
출처: 프로그래머스
첫 번째로 적이 맵의 (0,0)부터 (3,4)까지 공격하여 4만큼 건물의 내구도를 낮추면 아래와 같은 상태가 됩니다.
출처: 프로그래머스
두 번째로 적이 맵의 (2,0)부터 (2,3)까지 공격하여 2만큼 건물의 내구도를 낮추면 아래와 같이 4개의 건물이 파괴되는 상태가 됩니다.
출처: 프로그래머스
세 번째로 아군이 맵의 (1,0)부터 (3,1)까지 회복하여 2만큼 건물의 내구도를 높이면 아래와 같이 2개의 건물이 파괴되었다가 복구되고 2개의 건물만 파괴되어있는 상태가 됩니다.
출처: 프로그래머스
마지막으로 적이 맵의 (0,1)부터 (3,3)까지 공격하여 1만큼 건물의 내구도를 낮추면 아래와 같이 8개의 건물이 더 파괴되어 총 10개의 건물이 파괴된 상태가 됩니다. (내구도가 0 이하가 된 이미 파괴된 건물도, 공격을 받으면 계속해서 내구도가 하락하는 것에 유의해주세요.)
출처: 프로그래머스
최종적으로 총 10개의 건물이 파괴되지 않았습니다.
이 문제는 22년도 카카오 블라인드 채용 당시 직접 경험했던 문제다.
당시에는 갑작스러운 취업 준비로 인해 1주일 정도 밖에 공부하지 못했었고, 그래프 탐색, 최단경로, 누적합 등의 개념을 몰랐기에 전체 배열을 탐색하는 방법으로 밖에 시도해보지 못했다.
그리고 채용과정에 불합격한 후에 꾸준하게 코딩 테스트를 준비하다가 다시 만나게 되었다.
처음에는 이 전과 같이 2차원 배열을 skill 하나씩 탐색하며 board를 탐색하는 브루트포스 코드를 작성했었다.
def solution(board, skill):
answer = len(board) * len(board[0])
for s in skill:
if s[0] == 1:
for i in range(s[1], s[3]+1):
for j in range(s[2], s[4]+1):
flag = board[i][j] > 0 #원래는 정상적인 건물
board[i][j] -= s[5]
if flag and board[i][j] <= 0: # 공격받고 파괴되었는가 검사
answer -= 1
else:
for i in range(s[1], s[3]+1):
for j in range(s[2], s[4]+1):
flag = board[i][j] <= 0 #원래 파괴된 건물
board[i][j] += s[5]
if flag and board[i][j] > 0: #회복받고 복구되었는가 검사
answer += 1
return answer
제한 조건 중에
1 ≤ board의 원소 (각 건물의 내구도) ≤ 1,000
라는 조건이 있었기에 board 전체를 한번 더 탐색하지 않고 flag를 통해 접근하려는 앙큼한 생각이었지만, 문제는 skill 안에 있었다.
극단적인 예시로 board가 1,000*1,000일 때 skill의 길이가 최대인 250,000이고, 모든 skill의 원소가 항상 board 전체 범위를 타격할 때, 1,000*1,000의 범위를 250,000번이나 반복해서 연산하게 되므로 시간초과가 발생했다.
(시간 복잡도 O(N * M * K))
사실 처음에는 해결 방법을 찾지 못하고 열심히 서핑하였다.
그러다 카카오 팀에서 직접 밝힌 접근법에서 O(K + N * M)의 시간에 문제를 풀 수 있다고 했고, 그 방법의 중심에는 '누적합'의 개념이 있었다.
이 전까지는 한번도 사용해보지 않았던 알고리즘이라 생소하기도 하고 설명을 보아도 무슨 말인지 정확하게 이해 못하고 이게 왜 더 빠르지? 라는 의문도 가졌었다.
하지만 직접 작성해보고 테스트를 진행해보니 점차 이해가 갔고 결국에는 정답을 맞출 수 있었다.
<정답 코드>
def solution(board, skill):
answer = 0
tmp = [[0] * (len(board[0]) + 1) for _ in range(len(board) + 1)]
for type, r1, c1, r2, c2, degree in skill:
tmp[r1][c1] += degree if type == 2 else -degree
tmp[r1][c2 + 1] += -degree if type == 2 else degree
tmp[r2 + 1][c1] += -degree if type == 2 else degree
tmp[r2 + 1][c2 + 1] += degree if type == 2 else -degree
for x in range(len(tmp) - 1):
for y in range(len(tmp[0]) - 1):
tmp[x][y + 1] += tmp[x][y]
for y in range(len(tmp[0]) - 1):
for x in range(len(tmp) - 1):
tmp[x + 1][y] += tmp[x][y]
for x in range(len(board)):
for y in range(len(board[0])):
board[x][y] += tmp[x][y]
if board[x][y] > 0:
answer += 1
return answer
작성된 코드에 반복문이 너무 많이 보여 지저분하고 더 복잡해 보일 수 있지만, 해당 코드를 통해 문제를 접근하게 되면 항상 board 전체를 2번만 순회하게 되면 정답을 도출할 수 있다.
접근 방법은 아래와 같다.
board보다 행,열로 한 칸씩 더 큰 2차원 누적합 기록 배열을 생성한다.
skill을 순회하면서 하나의 skill이 나타내는 사각형의 꼭짓점(우측과 하단으론 한칸씩 더 증가시킨다)에 degree를 기록한다. (자세한 것은 누적합의 개념을 숙지해야 이해할 수 있다.)
기록된 누적합 배열의 행, 열 기준으로 누적합을 계산한다.
누적합 배열과 기존 board를 더해주면서 파괴되지 않은 건물의 수를 계산한다.
문제를 푸는 것에만 집중하면 쉬워보일 수 있는 문제였으나, 효율성을 고려하게 되면서 굉장히 어려워졌던 문제이다.
그리고 누적합의 설명은 보통 1차원 배열을 예시로 들기 때문에 개념을 이해하는데 어려움이 있었다.
그래도 고생 끝에 문제를 해결했기 때문에 오래 기억에 남을 것 같다.
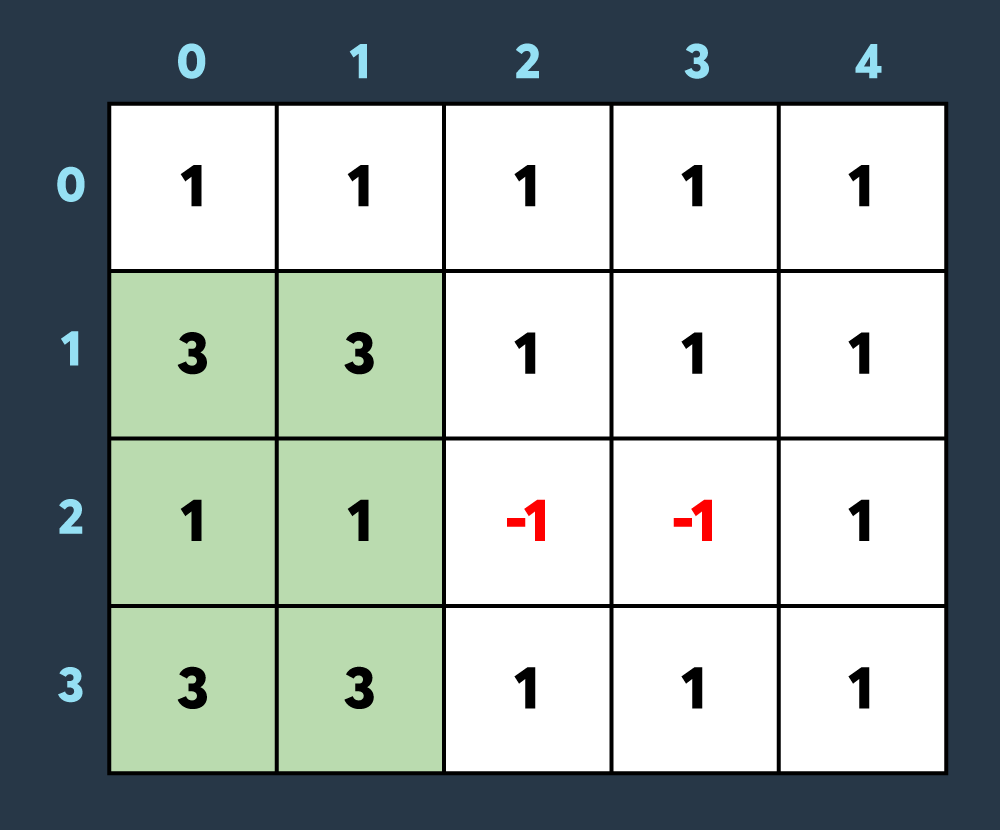
내가 이해한 2차원 누적합 개념 간단 설명
기존 배열이 5*5라고 가정하고 진행한다.
그렇게 되면 누적합 배열은 6*6이 되고 최초의 모습은 아래 사진과 같다.
이 상태에서 [0, 0]과 [1, 1]의 사각형이 들어왔다고 하자. 그렇다면 우리는 아래와 같이 기록해야한다.
우리가 원하는 것은 [0, 0]부터 [1, 1]까지 전부 1이 되는 그림이기 때문에 이렇게 기록해야 한다.
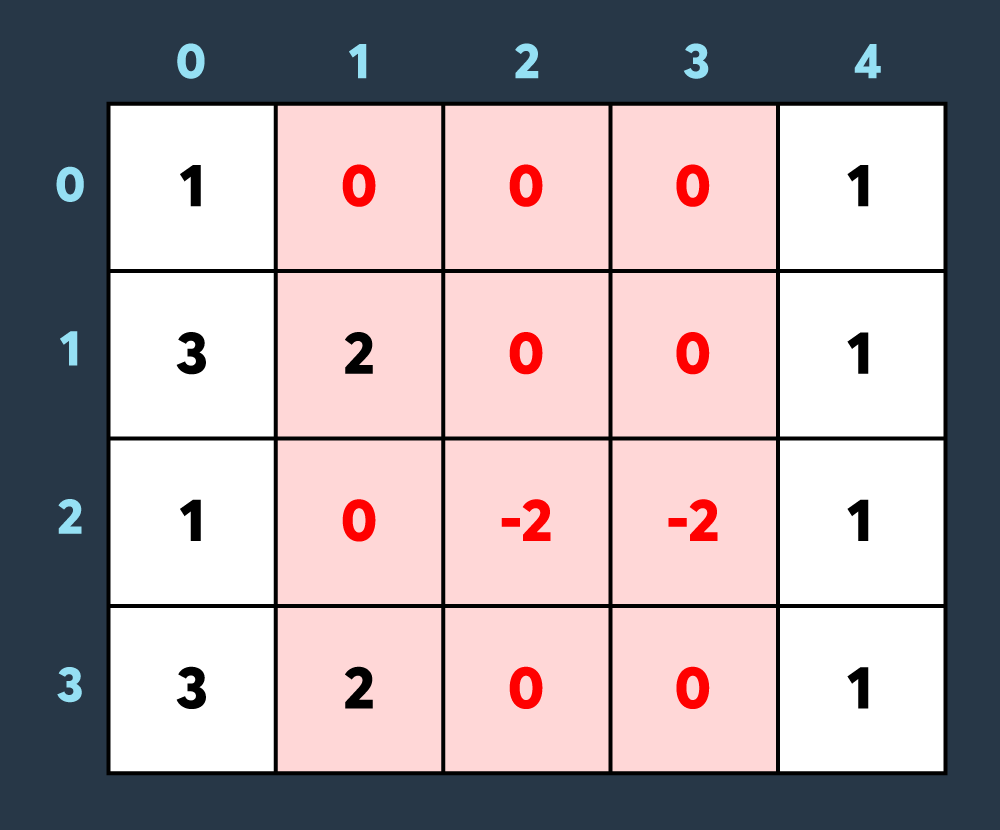
바로 누적합을 계산해서 결과를 확인해보자.
처음에는 행을 기준으로 누적합을 진행한다.
행을 기준으로 j+1번째 칸의 값이 현재 값에 j번째 칸의 값을 더한 값이 되므로 위와 같이 진행되었고, [0, 2]가 -1일 때 [0, 1]의 1과 더해지면서 0이 된 후는 전부 0+0이 된다.
(편의를 위해 0이 아닌 칸에 대해서만 진행했다.)
최종적으로 진행된 결과 값이 두 번째 사진처럼 된다.
이러한 원리로 또 열을 기준으로 합을 진행해보면,
최종적으로 이와 같이 나타나게 된다.
이렇게 되면 우리가 원했던 [0, 0], [1, 1]을 꼭짓점으로 가지는 사각형 만큼 값을 삽입하게 된 것이다.
이렇게 계산된 누적합 배열을 기존 board 배열에 더하게 되면 우리가 원하는 값이 도출될 것이다.
이렇게 문제를 푸는 것이 항상 빠르게 작용하는 것은 아니나, 브루트포스로 풀었을 때 예시를 든 것 같은 경우에는 이것이 훨씬 빨리 작동할 수 있다.
🔎1부터 N까지의 수를 이어서 쓰면 다음과 같이 새로운 하나의 수를 얻을 수 있다. (1 ≤ N ≤ 100,000,000) 1234567891011121314151617181920212223... 이렇게 만들어진 새로운 수는 몇 자리 수일까? 이 수의 자릿수를 구하는 프로그램을 작성하시오. (제한 시간: 0.15초, 파이썬은 0.5초)
해당 문제의 분류가 브루트포스로 되어있어서 설마 진짜 다 작성하고 len으로 구하는건가? 생각이 들어 작성해보니 역시나 시간초과가 떴다.
다른 방법을 생각했으나 해당 방법이 브루트포스인지는 명확하지 않다.
<정답 코드>
n = input()
cur = 1
answer = 0
while cur < len(n):
answer += cur * (10**cur - 10**(cur-1))
cur += 1
answer += cur * (int(n) - 10**(cur-1) + 1)
print(answer)
접근은 아래와 같다.
한 자리 수 부터 시작해 입력 받은 수의 자릿수 -1까지 (자릿수 * 해당 자릿수에 존재하는 숫자 개수)만큼을 더한다.
입력받은 수의 자릿수에 대해서는 (자릿수 * (입력받은 수 - 입력받은 수의 자릿 수의 첫번째 수))를 더한다.
한자리수일 때는 1~9, 9개가 존재하고, 두자리수일 때는 10~99, 90개, 세자리수는 100~999, 900개가 존재한다. 이와 같은 방법으로 계속 더 해나가는 것이다.
예를 들어 n = 1001이면 9+90+900+(4*2) = 1007이 되는 것이다.
내가 작성한 코드도 정답인 코드지만, 조금 더 직관적으로 작성하려면 while문 안에서 cur을 이용하기 보다 9로 시작해 9*10**(cur-1)로 진행해도 될 것 같다.
모든 숫자를 고려해야한다는 것은 사실이나, 기존 브루트포스 문제들과 같이 진짜 모든 경우를 방문하지 않는다는 점에서 브루트포스 문제인지 헷갈렸다.
🔎철수는 롤케이크를 두 조각으로 잘라서 동생과 한 조각씩 나눠 먹으려고 합니다. 이 롤케이크에는 여러가지 토핑들이 일렬로 올려져 있습니다. 철수와 동생은 롤케이크를 공평하게 나눠먹으려 하는데, 그들은 롤케이크의 크기보다 롤케이크 위에 올려진 토핑들의 종류에 더 관심이 많습니다. 그래서 잘린 조각들의 크기와 올려진 토핑의 개수에 상관없이 각 조각에 동일한 가짓수의 토핑이 올라가면 공평하게 롤케이크가 나누어진 것으로 생각합니다.
예를 들어, 롤케이크에 4가지 종류의 토핑이 올려져 있다고 합시다. - 토핑들을 1, 2, 3, 4와 같이 번호로 표시했을 때, 케이크 위에 토핑들이 [1, 2, 1, 3, 1, 4, 1, 2] 순서로 올려져 있습니다. - 만약 세 번째 토핑(1)과 네 번째 토핑(3) 사이를 자르면 롤케이크의 토핑은 [1, 2, 1], [3, 1, 4, 1, 2]로 나뉘게 됩니다. - 철수가 [1, 2, 1]이 놓인 조각을, 동생이 [3, 1, 4, 1, 2]가 놓인 조각을 먹게 되면 철수는 두 가지 토핑(1, 2)을 맛볼 수 있지만, 동생은 네 가지 토핑(1, 2, 3, 4)을 맛볼 수 있으므로, 이는 공평하게 나누어진 것이 아닙니다. - 만약 롤케이크의 네 번째 토핑(3)과 다섯 번째 토핑(1) 사이를 자르면 [1, 2, 1, 3], [1, 4, 1, 2]로 나뉘게 됩니다. - 이 경우 철수는 세 가지 토핑(1, 2, 3)을, 동생도 세 가지 토핑(1, 2, 4)을 맛볼 수 있으므로, 이는 공평하게 나누어진 것입니다. - 공평하게 롤케이크를 자르는 방법은 여러가지 일 수 있습니다. 위의 롤케이크를 [1, 2, 1, 3, 1], [4, 1, 2]으로 잘라도 공평하게 나뉩니다.
어떤 경우에는 롤케이크를 공평하게 나누지 못할 수도 있습니다.
제한사항 - 1 ≤ topping의 길이 ≤ 1,000,000 - 1 ≤ topping의 원소 ≤ 10,000
본 문제는 아주 간단한 문제이지만 시간 복잡도를 어떻게 개선하느냐에 관한 문제였다.
topping을 1번 순회하는데만 1,000,000번의 연산이 수행되므로, 파이썬에서는 O(n)으로 구현해야 1초 안에 문제가 해결된다고 볼 수 있다.
🔎 N개의 스티커가 원형으로 연결되어 있습니다. 다음 그림은 N = 8인 경우의 예시입니다.
원형으로 연결된 스티커에서 몇 장의 스티커를 뜯어내어 뜯어낸 스티커에 적힌 숫자의 합이 최대가 되도록 하고 싶습니다. 단 스티커 한 장을 뜯어내면 양쪽으로 인접해있는 스티커는 찢어져서 사용할 수 없게 됩니다.
예를 들어 위 그림에서 14가 적힌 스티커를 뜯으면 인접해있는 10, 6이 적힌 스티커는 사용할 수 없습니다. 스티커에 적힌 숫자가 배열 형태로 주어질 때, 스티커를 뜯어내어 얻을 수 있는 숫자의 합의 최댓값을 return 하는 solution 함수를 완성해 주세요. 원형의 스티커 모양을 위해 배열의 첫 번째 원소와 마지막 원소가 서로 연결되어 있다고 간주합니다.
- sticker는 원형으로 연결된 스티커의 각 칸에 적힌 숫자가 순서대로 들어있는 배열로, 길이(N)는 1 이상 100,000 이하입니다. - sticker의 각 원소는 스티커의 각 칸에 적힌 숫자이며, 각 칸에 적힌 숫자는 1 이상 100 이하의 자연수입니다. - 원형의 스티커 모양을 위해 sticker 배열의 첫 번째 원소와 마지막 원소가 서로 연결되어있다고 간주합니다.
스티커 모으기1 문제는 풀어보지 않았지만, 이와 비슷한 문제가 백준에서도 존재한다.
문제 유형 자체는 전형적인 DP 문제로 백준의 건물 색칠하기 문제와 유사하다.
문제에서 스티커가 원형이 아니었으면 하나의 DP배열을 이용해서 간단히 해결할 수 있지만, 원형이기 때문에 고려해야 할 사항이 추가된 셈이다.
<정답 코드>
def solution(sticker):
n = len(sticker)
if n == 1:
return sticker[0]
if n == 2:
return max(sticker)
dp1, dp2 = [0] * n, [0] * n
dp1[0] = sticker[0]
dp1[1] = max(sticker[0], sticker[1])
dp2[1] = sticker[1]
dp2[2] = max(sticker[1], sticker[2])
for i in range(2, n):
dp1[i] = max(dp1[i - 1], dp1[i - 2] + sticker[i]) if i < n-1 else dp1[i]
dp2[i] = max(dp2[i - 1], dp2[i - 2] + sticker[i]) if 2 < i else dp2[i]
return max(max(dp1), max(dp2))
접근 방법은 아래와 같다.
1. 0번 index의 스티커를 사용하는 배열 dp1, 사용하지 않는 배열 dp2를 생성한다.
1-1. dp1배열은 마지막 스티커를 제외한 n-1개의 스티커를 사용하고, dp2는 0번 스티커를 제외한 n-1개의 스티커를 사용한다.
2. 각 dp배열에서 처음 사용하게 되는 스티커는 sticker[i]로 초기화 해주고, 두번째로 사용하게 되는 스티커는 첫번째 스티 커와 비교해 더 큰 값으로 지정한다.
3. 앞의 스티커를 사용했을 경우, 바로 다음 스티커는 이용할 수 없으므로 dp[i-1]과 dp[i-2] + sticker[i]를 비교해 max값을 dp[i]에 삽입한다. (1-1을 어기지 않도록 작성한다.)