셀레니움을 이용한 웹크롤링(Web crawling)
오늘 배울것은 셀레니움(selenium)라이브러리를 이용한 웹 정보수집 (Web crawling)을 해볼것이다.
사용할 library로는 selenium과 beautiful soup 이 있다.
둘에 대해 간략하게 설명하자면,
-selenium : 주로 웹앱을 테스트하는 프레임 워크다. 각 웹앱에 맞는 driver를 통해서 웹을 직접 조작하며 결과물을 불러올 수 있다.
-bs4(Beautiful Soup) : html 구조를 파이썬이 이해할 수 있도록 변환하는 parsing을 맡고 있는 라이브러리. 의미가 있는 결과물을 불러낼 때 사용한다.
이것들을 이용해 두번의 예제에 걸쳐서 학습해보도록 하자.
#에브리타임 게시판 글 가져오기.

우선 필요한 라이브러리들을 전부 호출해줬다 selenium과 bs4, csv는 앞서 설명을 진행하였다.
그렇다면 time sleep은 무엇일까?
쉬어가겠다는 의미이다. 그렇다면 우리는 왜 정보를 수집할 때 쉬어가야하는걸까?
우리가 인터넷 사이트에 직접적으로 접속할 때 일정시간이 소요된다. 하지만 셀레니움을 이용해 이에 접근할 때는 우리가 접속할 대 소모되는 시간을 무시하고 빠르게 진행이 된다. 이렇게 되면 웹 사이트에서 우리를 해킹툴로 인식해 차단할수도 있고, 웹에 과부하를 줄 수도있다. 그러므로 되도록이면 sleep을 사용해 쉬어들어가도록 하자.
csv파일을 사용하는데 wt+는 처음보는것 같..지만 사실은 알고있는 범위 내다.
w : 쓰기모드
t : 텍스트모드
+ : 업데이트를 위해 열기
세개를 조합해서 쓴 것이다. 우리는 웹에서 데이터를 따와서 csv파일에 저장할 것 이므로 이렇게 써줬다.
웹앱은 요즘 정말 많이 존재한다. (firefox, naverwhale, chrome, IE ...)
firefox 앱이 셀레니움에 최적화 되어있지만 우리는 보편적으로 깔려있는 chrome을 써서 웹을 수집할 것이므로 chromedriver를 이용해주도록하자.
크롬 드라이버는 밑에 주소에서 설치할 수 있다.
https://chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
버전 정보는 크롬을 실행한뒤, 설정 -> chrome 정보에서 확인할 수 있다.
설치를 하면 이것을 불러와줘야하는데 이건 csv파일 호출할 때와 마찬가지로 같은 폴더 안에 집어넣어 놓으면 바로 불러올 수 있지만, 다른 폴더안에 저장해놓았으면 위의 코드와 같이 직접호출을 해줘야한다.
호출을 해준 뒤, get 매서드를 이용해서 원하는 홈페이지를 불러온다.
이 다음에 나오는 xpath에 대한 개념을 살짝 정리하고 들어가자면,
xpath : 특정 요소(element)를 찾을 때 접근할 수 있게 해주는 언어로 이것을 이용해 각 요소로 접근을 할 수 있다.
그리고 get 다음에 나오는 implicity_wait은 sleep과 구분하기 위해서 집어넣어놨다.
implicity_wait(10)의 의미는 웹이 응답할 때 까지 최대 10s만큼을 기다려주겠다는 의미이다.
sleep과의 차이점은 sleep은 반드시 지정한 초만큼 지연시키지만, implicity_wait는 웹이 응답할 때 까지만 기다리는 것이다.
그 다음부터는 본론이다.
우선 로그인을 해서 권한을 얻어야 게시판에 접근할 수 있으므로 로그인을 먼저해보도록 하자.
위에서 설명한 xpath로 접근하기 위해서 우리는 개발자모드로 들어가야한다. (크롬은 f12를 누르면 들어갈 수 있다.)
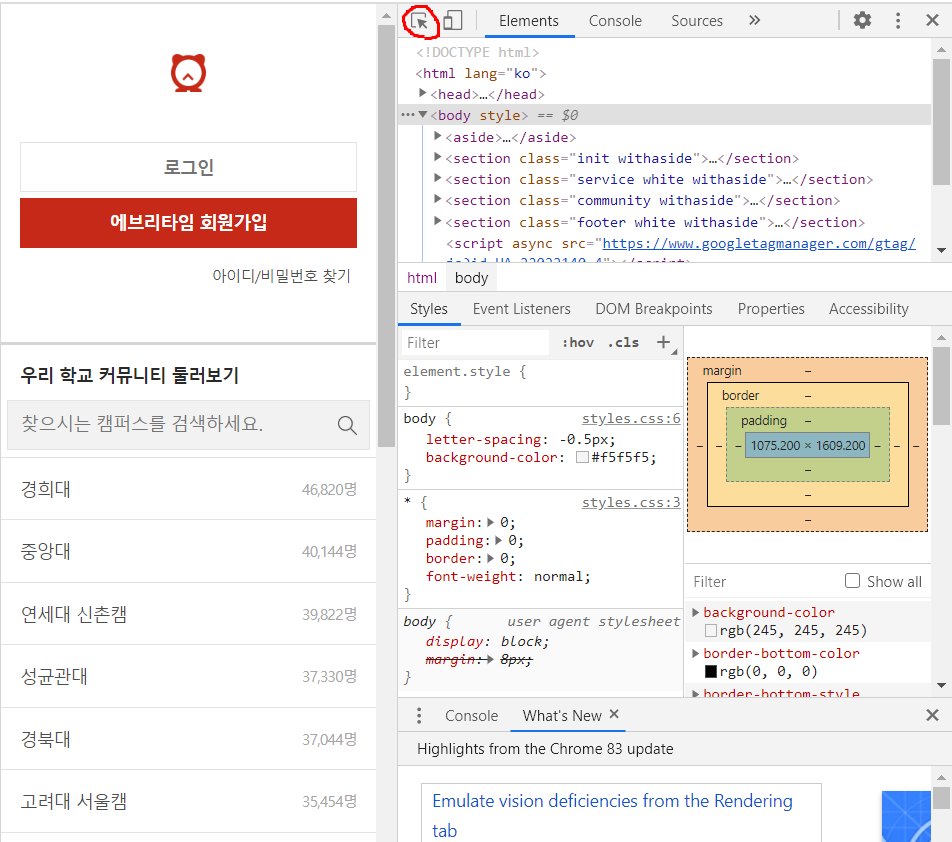
개발자 모드의 모습이다.
우리는 xpath로 접근을 하기 위해서 위에 빨간색으로 동그라미 친 부분을 누르고 로그인 버튼을 누르면

사진과 같이 회색으로 클릭된 부분이 개발자 환경 화면에 나온다.
여기서 이 부분을 우클릭한 후 copy에 마우스를 얹으면 아래쪽에 copy xpath가 뜨는데 이것을 누르면 xpath가 복사된다.
이 후 로그인까지 모든 과정을 위와 같이 진행하면 된다.
click과 sendkey는 무엇일까?
이건 그냥 말 그대로 그 버튼을 click 한다는 의미와 아이디 비밀번호 (혹은 그 이외의 정보를 입력해주어야하는 것)을 파이썬에서 입력시키게 하기 위해서 사용한 것이다.
로그인을 마친 후 우리가 원하는 게시판으로 이동하는 것 까지 xpath로 진행을 해주면 된다. (나는 자유게시판으로 갔다)
그 이후에는 bs4를 이용해서 html구문을 해석시켜준 후 데이터를 수집할 수 있게 해야한다.
그래서 보이는 페이지의 html을 그대로 가져오기 위해서 driver.page_source를 html이라는 변수에 저장해 현재 페이지를 분석할 수 있게 해준다.
이 후에 html을 bs4를 이용해 parsing해준다.
자유게시판에 올라와있는 글들은 제목과 내용으로 구분되어 있는데, 이를 각각 가져와줘야한다. ( 둘의 element가 다르기 때문에 한번에 가져올 수가 없다.)
이번에는 selector를 이용해서 정보를 가져올것이다.
css selector : 말 그대로 선택을 해주는 요소이다. 각 요소마다 스타일을 지정해줄 수 있다.
이것도 xpath 복사한것과 같은 경로로 들어간 후 copy seletor를 클릭해주면 된다.
하지만 우리는 게시판에 있는 한 요소만 가져오거나 접속할게 아니기 때문에 전체적인 부분을 써넣어줘야한다.
그냥 selector를 복사해서 붙여넣기만 하면 내가 가져온 글의 selector만 저장할 수 있으므로 조심하도록하자.

그냥 첫번째 글과 두번째 글의 selector를 가져와봤을 때 위에 사진처럼 나온다. 공통되는 구문도 있지만, nth-child(n) 이부분이 다르다.
그러므로 깔끔하게 저 부분을 지우면, 위에 써놓은 코드처럼 나오게 된다.
제목을 가져왔으니까 내용도 같은 원리로 가져와준 후, 반복문을 통해서 리스트형으로 csv파일에 덮어 씌워주면 끝이다!
결과물:


csv파일과 컴파일러에서 확인할 수 있다..! (나의 학교와 학우들을 위해서 블러처리했다..)
#인스타그램 사진 크롤링하기

들어가기 전에 urlib에 대해서 알아보자.
urllib은 url에 관련된 library를 가져오는데 사용된다. 그 중에서 우리는 request와 parse를 사용할 것이다.
request는 말 그대로 url을 요청(가져오기)위해 사용하는 모듈로, urlopen형태로 쉽게 가져올 수 있다.
parse는 url을 파싱, 다루기 위해 사용하는 모듈이다.
quote_plus는 url을 인용할 때 쓰는 함수인데 미리 기억해두도록하자.
baseurl에서 인스타그램 태그 검색을 기반으로 둔 채, plusurl에서 내가 검색할 태그를 input매서드를 통해서 입력받도록 한 후,
내가 원하는 검색결과를 가져오기 위해서 baseurl + quote_plus(plusurl)로 최종 url을 설정했다.
이후 과정은 앞서 말한 내용과 동일하므로 생략하고,
정보를 선택하기 위해서 html에서 가져올 element를 찾아보자.

개발자 모드에서 보면, 사진에 해당하는 element는 v1Nh3~~에 해당하는 구문임을 쉽게 알 수 있다.
우리가 원하는 것은 사진에 해당하는 element만 있으면 되기 때문에 v1Nh3~를 가져오도록하자.
여기서 주의해야할 점은, html구문 상에 존재하는 블랭크는 전부 .으로 채워주어야 한다는 것이다.
이 후 반복문을 통해서 이미지들을 가져올건데, 몇가지 설명해야할 것이 있다.
href : a라는 문서를 연결하는 태그의 href라는 방식이다. a태그의 연결할 주소를 지정해준다.
src : 태그의 미디어를 재생할 때 사용되는 속성이다.
select : 내가 원하는 정보를 찾기 위한 매서드.
위의 정보들을 조합해서 반복문을 쑤셔보면,
내가 가져올 이미지의 태그의 url을 프린트 한 후, imgurl속에 내가 검색한 태그의 이미지의 정보를 저장한 뒤, 한번 더 반복문을 실행하여 img라는 폴더안에 그 내용을 저장하겠다는 의미를 담고있다.
이러나 저러나 실행을 시켜보면,,


이미지에 해당하는 url에 대해서 열심히 출력을 한 후 이미지를 저장한 모습까지 완벽하다!.
20.06.03